
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- github
- 탐욕알고리즘
- Django
- java
- 백준
- sort
- SQL
- programmers
- 장고
- 코딩테스트
- Riot
- 프로그래머스
- 리그오브레전드
- 롤
- drf
- 그리디
- 그리디알고리즘
- 자바
- 내일배움캠프
- lol
- greedy
- python
- 파이썬
- API
- git
- 스파르타내일배움캠프
- 코딩테스트준비
- 스파르타내일배움캠프TIL
- 알고리즘
- 라이엇
- Today
- Total
Lina's Toolbox
SQL 실행 환경 설정, SQL 기초 / AS, 비교연산, SUM, AVG, COUNT, MIN, MAX, GROUP BY, ORDER BY 본문
SQL 실행 환경 설정, SQL 기초 / AS, 비교연산, SUM, AVG, COUNT, MIN, MAX, GROUP BY, ORDER BY
Woolina 2024. 8. 6. 22:34
데이터 베이스
데이터베이스(Database)는 데이터를 체계적으로 저장, 관리, 검색할 수 있도록 설계된 구조화된 데이터 집합
실습 환경 설정
1. DBeaver 설치
* DBeaver: SQL을 보다 손쉽게 사용할 수 있도록 도와주는(DBMS와 상호작용하기 위한) SQL 클라이언트 도구
다운로드 링크: https://dbeaver.io/download/

각자 운영체제에 맞게 설치합니다.
2. 설치한 DBeaver를 실행합니다
3. 좌측 상단 플러그 모양의 아이콘을 클릭합니다

4. 새 창이 뜨면, MySQL을 선택하고 '다음' 버튼을 누릅니다

5. 아래와 같이 정보를 입력하고 좌측 하단 'Test Connection' 버튼을 클릭합니다.
Server Host:
sparta.cbt9ceqjwlr9.ap-northeast-2.rds.amazonaws.com
Database: sparta
Username: sparta_student
Password: sparta99

6. 만약 Driver가 설치되어있지 않으면 아래와 같은 창이 뜹니다. 다운로드 버튼을 눌러줍니다.

7. Connection Test 결과에 'Connected'라고 뜨면, 확인 버튼을 누르고 완료 버튼을 눌러줍니다.


양탄자 기호의 SQL 버튼을 눌러주면 쿼리를 작성할 수 있다.
쿼리 실행은 이 실행 버튼(▶️) 혹은 ctrl + enter 단축키로 가능 하다.
컬럼에 별명(alias) 을 주기
- 원하는 컬럼만 뽑았지만, 평소에 사용하는 명칭과 다를 때가 있습니다. 이럴 때 컬럼 명에 별명을 지정하여 변경할 수 있습니다.
- 별명 지정 방법 : 컬럼 옆쪽에 별명을 적어줍니다. (아래 두 가지 방법 모두 가능합니다)
- 방법1 : 컬럼1 as 별명1
- 방법2 : 컬럼2 별명2
- 별명 지을 때 유의사항
구분 영문, 언더바 특수문자, 한글 방법 별명만 적음 “별명” 으로, 큰 따옴표 안에 적어줌 예시 ord_no “ord no”
”주문번호” - 위의 예시에서 ‘주문 번호’ 와 ‘식당 이름’을 조회했는데요, 컬럼명이 너무 길고 영문이라 보기가 어려웠습니다. 이 때 별명을 아래와 같이 지어줘봅시다.
- order_id → ord_no
- restaurant_name → 식당 이름
select order_id as ord_no,
restaurant_name "식당 이름"
from food_orders실행을 누르면, 컬럼명이 원하는 별명으로 바뀐 것을 확인할 수 있습니다.

필터링을 할 때 유용한 표현 알아보기 (비교연산, BETWEEN, IN, LIKE)
1. 같음, 큼, 작음 등의 조건을 지정해보기
- 필터링은 같다 (=) 조건을 포함하여, 크다 (>), 작다 (<) 등을 모두 사용할 수 있습니다.
- 비교연산자의 종류
| 비교연산자 | 의미 | 예시 |
| = | 같다 | age=21 gender=’female’ |
| <> | 같지 않다 (다르다) | age<>21 gender<>’female’ |
| > | 크다 | age>21 |
| >= | 크거나 같다 | age>=21 |
| < | 작다 | age<21 |
| <= | 작거나 같다 | age<=21 |
2. 다양한 조건의 종류 (BETWEEN, IN, LIKE)
BETWEEM : A 와 B 사이
기본 문법 : between a and b
예시 : 나이가 10 과 20 사이
where age between 10 and 20
IN : ‘포함’ 하는 조건 주기
기본 문법 : in (A, B, C)
예시1 : 나이가 15, 21, 31 세인 경우
age in (15, 21, 31)
예시2 : 음식 종류가 한식, 일식인 경우
cuisine_type in ('Korean', 'Japanese')
LIKE : 완전히 똑같지는 않지만, 비슷한 값을 조건으로 주기 특정한 문자로 시작하는 경우
기본 문법 : like ‘시작문자%’
예시 : ‘김’ 으로 시작하는 이름
name like '김%'
특정한 문자를 포함하는 경우
기본 문법 : like ‘%포함문자%’
예시 : 식당 이름에 ‘Next’ 를 포함하는 경우
restaurant_name like '%Next%'
특정한 문자로 끝나는 경우
기본 문법 : like ‘%시작문자’
예시 : ‘임’ 으로 끝나는 이름
name like '%임'엑셀 대신 SQL로 한번에 계산하기 (SUM, AVERAGE, COUNT, MIN, MAX)
숫자 연산
| 연산자 | 설명 |
| + | 더하기 |
| - | 빼기 |
| * | 곱하기 |
| / | 나누기 |
숫자연산 예시
select food_preparation_time,
delivery_time,
food_preparation_time + delivery_time as total_time
from food_orders
기본 연산, 합계와 평균 구하기전체 데이터의 갯수 구하기
합계와 평균은 엑셀에서만 구할 수 있다? No! SQL 에서 바로 구할 수 있습니다
- 함수 종류
- 합계 : SUM(컬럼)
- 평균 : AVG(컬럼)
- 사용 예시 (상품 준비시간의 합계와 평균 구하기)
select sum(food_preparation_time) total_food_preparation_time,
avg(delivery_time) avg_food_preparation_time
from food_orders
데이터의 범위, 최솟값과 최댓값 구하기
- 함수 종류
- 최솟값 : MIN(컬럼)
- 최댓값 : MAX(컬럼)
- 사용 예시 (주문 가격의 최솟값, 최댓값 구하기)
select min(price) min_price,
max(price) max_price
from food_orders
전체 데이터의 갯수 구하기
현재 테이블이 몇 개의 데이터를 가지고 있는지, 몇 개의 값을 가지고 있는지도 구할 수 있습니다.
- 함수 종류
- 데이터 갯수 : COUNT(컬럼) * 컬럼명 대신 1 혹은 * 사용 가능
- 몇개의 값을 가지고 있는지 구할 때 : DISTINCT
- 예시
- 데이터 갯수 : 주문 테이블의 전체 주문은 몇건인가요?
- 몇개의 값을 가지고 있는지 구할 때 : 주문을 한 고객은 몇명인가요?
- 사용 예시 (주문건수와, 주문 한 고객 수 구하기)
select count(1) count_of_orders,
count(distinct customer_id) count_of_customers
from food_orders
count(1) : 이 테이블 안에 있는 모든 데이터의 갯수
count(distinct 컬럼명): 이 컬럼이 가진 값의 갯수 (customer_id = 고객의 갯수)
💡 이런식으로 select 옆에 distinct를 적어주면, 결과값에서 중복이 알아서 제거되어 출력된다!
SELECT DISTINCT * from food_orders
GROUP BY로 범주별 연산 한 번에 끝내기
음식 종류별로 평균 음식 가격을 구하기 위해 where 절을 사용해서 수십개의 쿼리를 작성하는 것은 너무 비효율적입니다.
이 문제를 Group by를 사용해서 어떻게 해결할 수 있을까요?
- 여러번의 Query 없이, 카테고리를 지정하여 수식 함수로 연산을 할 수 있습니다.
- 이 때 사용되는 구문이 Group by 입니다.
Group by 기본 구조
select 카테고리컬럼(원하는컬럼 아무거나),
sum(계산 컬럼),
from
group by 카테고리컬럼(원하는컬럼 아무거나)
사용 예시 (음식 종류별 주문 금액 합계)
select cuisine_type,
sum(price) sum_of_price
from food_orders
group by cuisine_type
이때 GROUP BY를 꼭 써줘야한다.
만약 group by를 쓰지 않는 다면 다음과 같이 출력된다.

결제 타입별 가장 최근 결제일 조회하기
최근 -> MAX(date타입) 이용!!
select pay_type "결제타입",
max(date) "최근 결제일"
from payments
group by pay_type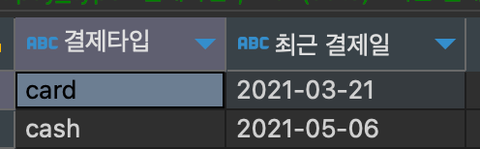
Query 결과를 정렬하여 업무에 바로 사용하기 (ORDER BY)
정렬문 Order by 의 기본구조
- Order by 는 카테고리 컬럼 지정, 그리고 Order by 를 적어주는 것으로 적용 가능합니다.
- 기본 구조
select 카테고리컬럼(원하는컬럼 아무거나),
sum(계산 컬럼),
from
group by 카테고리컬럼(원하는컬럼 아무거나)
order by 정렬을 원하는 컬럼 (카테고리컬럼(원하는컬럼 아무거나), sum(계산 컬럼) 둘 다 가능)
예시
select cuisine_type,
sum(price) sum_of_price
from food_orders
group by cuisine_type
order by sum(price)
order by 끝에 DESC를 써준다면 내림차순 정렬이 된다.
select restaurant_name,
max(price) "최대 주문금액"
from food_orders
group by restaurant_name
order by max(price) desc예제
음식 종류별 가장 높은 주문 금액과 가장 낮은 주문금액을 조회하고, 가장 낮은 주문금액 순으로 (내림차순) 정렬하기
select cuisine_type,
min(price) min_price,
max(price) max_price
from food_orders
group by cuisine_type
order by min(price) desc'스파르타 내일 배움 캠프 AI 웹개발 과정 > Database & SQL' 카테고리의 다른 글
| 개체 관계 다이어그램 (ERD)작성법 (0) | 2024.08.14 |
|---|---|
| SQL Window function - RANK, SUM / SQL 피벗(Pivot) 만들기 / 포맷함수 (0) | 2024.08.09 |
| SQL 서브쿼리(Subquery) 와 조인(Join) (0) | 2024.08.08 |
| SQL 문자 데이터 가공하기 / replace, substring(substr), concat, if, case (0) | 2024.08.07 |



