
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- drf
- 리그오브레전드
- 그리디알고리즘
- 알고리즘
- 내일배움캠프
- 탐욕알고리즘
- Django
- 코딩테스트준비
- java
- 백준
- SQL
- API
- Riot
- 스파르타내일배움캠프
- 롤
- 라이엇
- 프로그래머스
- sort
- git
- programmers
- 장고
- greedy
- 스파르타내일배움캠프TIL
- lol
- 파이썬
- 자바
- 그리디
- 코딩테스트
- python
- github
- Today
- Total
Lina's Toolbox
[내일배움캠프_챌린저반] 기술면접 오답노트 본문
챌린저 반 중에서 합격자가 3명 뿐이라는데 내가 그 중 한명이라니 뿌듯하다 ㅎㅎ
면접있는 날 한 숨도 못자고 밤새서 공부한 보람이 있다!!!
잘 하고 있구나 확인받는 느낌 ㅎㅎ
다행히 공부했던 부분에서 문제가 다 나왔다.

학습을 위해서 맞춘 문제도 더 깔끔하고 정확한 답변을 찾아 정리해보려고 한다.
📌 배열과 링크드 리스트의 차이점은?
- 배열은 연속적인 메모리 블록에 요소를 저장하여 빠른 읽기 속도와 단순한 구현을 제공하지만, 크기가 고정되어 있으며 중간 삽입과 삭제가 비효율적입니다.
- 링크드 리스트는 각 요소(노드)가 데이터와 다음 노드에 대한 참조를 가지고 있는 자료구조로, 노드는 순서대로 연결되어 있으며, 메모리 상에서 연속적으로 배치되지 않을 수 있습니다. 동적 크기 조정이 가능하고 삽입 및 삭제가 효율적이지만, 비연속적인 메모리 배치와 느린 접근 속도가 단점입니다.

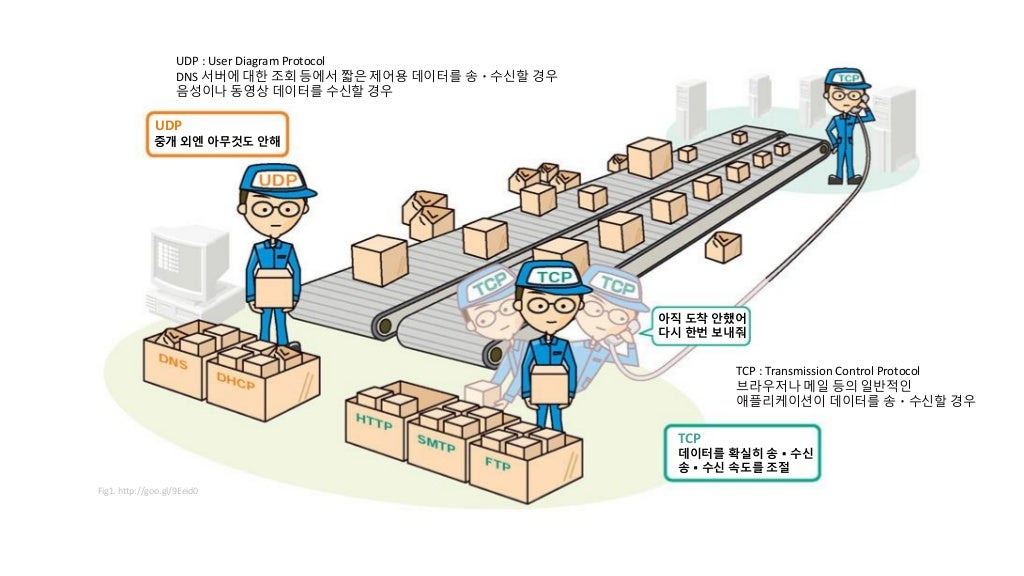
📌 TCP와 UDP의 차이점은? (유튜브에 빗대어 설명하시오.)

TCP (Transmission Control Protocol)
TCP는 유튜브에서 비디오를 스트리밍하는 경우와 비슷합니다.
- 순서 보장: TCP는 데이터 패킷이 전송된 순서대로 도착하도록 보장합니다.
- 연결지향적: TCP는 신뢰성 있는 연결을 제공합니다. 클라이언트와 서버 간의 연결이 설정된 후, 데이터 전송을 시작합니다. 이 연결은 양쪽이 데이터 전송이 완료될 때까지 유지됩니다.
- 오류 검출 및 수정: CP는 데이터 전송 중 발생할 수 있는 오류를 검출하고 수정합니다. 데이터가 손실되거나 손상되면 재전송을 통해 이를 복구합니다.
UDP (User Datagram Protocol)
UDP는 유튜브에서 라이브 스트리밍을 하는 경우와 비슷합니다.
- 비연결 지향적: 유튜브 라이브 스트리밍에서는 사전에 서버와 클라이언트 간의 연결을 설정하지 않습니다. 데이터가 방송되는 순간 즉시 전송되며, 연결 설정이 필요 없습니다.
- 오류 검출 및 수정 없음: 라이브 스트리밍에서는 데이터의 정확성과 순서가 반드시 보장되지 않아도 됩니다. 데이터가 손실되거나 오류가 발생하더라도, 라이브 방송의 흐름에는 큰 문제가 되지 않습니다. 즉, UDP는 오류 검출과 수정 기능이 제한적입니다.
- 순서 보장 없음: 라이브 스트리밍에서는 데이터 패킷의 순서가 중요하지 않을 수 있습니다. 데이터가 불규칙하게 도착하더라도 방송이 지속되며, 화면의 일시적인 끊김이나 품질 저하로 인식될 수 있습니다.
- 빠른 전송: UDP는 연결 설정 및 오류 복구 과정을 생략하므로 빠른 전송이 가능하며, 지연이 적어 실시간 통신에 적합합니다. 유튜브 라이브 스트리밍처럼 지연이 중요한 경우 UDP의 특성이 유리할 수 있습니다.
요약
- TCP: 순서를 보장하고 오류를 관리하며 전송하여 보안과 정확성을 더 중요시 합니다. 유튜브 비디오 스트리밍처럼 안정적인 데이터 전송과 정확성이 보장될 때 적합합니다.
- UDP: 보안과 정확성보다는 속도가 중요하고 지연이 적어야하는 데이터 전송에 사용합니다. 유튜브 라이브 스트리밍처럼 빠르고 실시간으로 데이터를 전송하지만, 데이터의 정확성과 순서를 보장하지 않습니다.
📌 추가질문: 그렇다면 로그인 기능을 구현할 때 사용하는 네트워크 프로토콜은 TCP or UDP?
로그인 기능 자체는 TCP와 UDP의 어느 하나에 속하는 것이 아닙니다.
대신, 로그인 기능을 구현할 때 사용하는 네트워크 프로토콜은 일반적으로 TCP입니다.
로그인에서의 데이터 전송은 속도보다는 신뢰성, 데이터 무결성, 연결 안정성이 중요한 작업입니다.
이러한 요구를 충족시키기 위해 TCP가 일반적으로 사용됩니다.
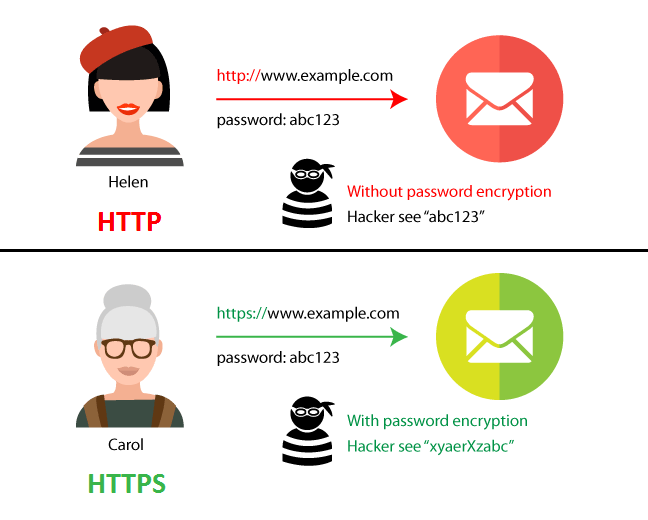
📌 HTTP와 HTTPS의 차이점?
HTTP (HyperText Transfer Protocol)
- 기능: 웹 서버와 클라이언트(브라우저) 간의 데이터 전송을 처리합니다.
- 보안: 데이터 전송 시 암호화되지 않으며, 중간에서 데이터가 가로채이거나 변조될 수 있습니다.
HTTPS (HyperText Transfer Protocol Secure)
- 기능: HTTP의 보안 버전으로, 데이터 전송 시 암호화가 적용됩니다.
- 보안: 데이터가 암호화되어 전송되며, 중간에서 데이터가 가로채이거나 변조되는 것을 방지합니다.
📌 HTTPS의 암호화 방식
- 비대칭키 암호화:
- 설명: 공개키와 개인키 쌍을 사용하여 데이터를 암호화하고 복호화합니다. 공개키로 암호화된 데이터는 개인키로만 복호화할 수 있습니다.
- HTTPS에서의 역할: 서버와 클라이언트 간의 초기 핸드셰이크 과정에서 비대칭키 암호화가 사용되어 안전한 연결을 설정합니다.
- 대칭키 암호화:
- 설명: 동일한 키로 데이터를 암호화하고 복호화합니다. 대칭키는 빠르고 효율적입니다.
- HTTPS에서의 역할: 비대칭키 암호화로 안전하게 교환된 대칭키를 사용하여 실제 데이터 전송을 암호화합니다. 이 과정은 데이터 전송의 성능을 향상시킵니다.
- SSL (Secure Sockets Layer):
- 설명: HTTPS에서 사용되는 프로토콜로, 데이터 전송 중 암호화를 제공합니다. SSL의 후속 버전으로 TLS (Transport Layer Security)가 있으며, 현재는 TLS가 널리 사용됩니다.
- HTTPS에서의 역할: SSL/TLS는 HTTP 위에 추가되어 데이터 전송을 암호화하고 보안을 강화합니다.
요약
- HTTP: 암호화되지 않은 데이터 전송.
- HTTPS: SSL/TLS를 사용하여 데이터 전송을 암호화하고 보안을 강화.
- 비대칭키: 초기 암호화 설정 및 키 교환에 사용.
- 대칭키: 실제 데이터 전송 암호화에 사용.
- SSL/TLS: HTTPS에서 데이터 전송을 암호화하는 프로토콜.
📌 객체지향 프로그래밍의 4가지 주요 개념은 무엇인가?
1. 캡슐화 (Encapsulation)
- 정의: 데이터(속성)와 그 데이터를 처리하는 메서드(함수)를 하나의 단위(객체)로 묶는 것입니다. 이를 통해 객체의 내부 상태를 숨기고, 외부에서는 객체가 제공하는 인터페이스를 통해서만 상호작용할 수 있습니다.
- 장점: 객체의 내부 구현을 변경하더라도 외부 코드에 영향을 주지 않으므로 유지보수가 용이합니다. 또한, 데이터의 무결성을 보장할 수 있습니다.
🔽 예시
class Person:
def __init__(self, name, age):
self.__name = name # private 변수
self.__age = age # private 변수
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def get_age(self):
return self.__age
def set_age(self, age):
if age > 0:
self.__age = age
else:
print("Age must be positive")
person = Person("Alice", 30)
print(person.get_name()) # Alice
person.set_age(31)
print(person.get_age()) # 312. 상속 (Inheritance)
- 정의: 기존 클래스(부모 클래스)의 속성과 메서드를 새로운 클래스(자식 클래스)에서 재사용할 수 있는 기능입니다. 자식 클래스는 부모 클래스의 특성을 상속받으며, 추가적인 기능이나 특성을 정의할 수 있습니다.
- 장점: 코드 재사용을 촉진하고, 계층적인 관계를 통해 코드의 구조를 명확하게 할 수 있습니다.
🔽 예시
class Animal:
def speak(self):
return "Animal sound"
class Dog(Animal):
def speak(self):
return "Bark"
class Cat(Animal):
def speak(self):
return "Meow"
dog = Dog()
cat = Cat()
print(dog.speak()) # Bark
print(cat.speak()) # Meow3. 다형성 (Polymorphism)
- 정의: 동일한 메서드 호출이 객체의 종류에 따라 다르게 동작할 수 있는 능력입니다. 다형성은 주로 메서드 오버로딩(다양한 매개변수를 가진 메서드 정의)과 메서드 오버라이딩(부모 클래스의 메서드를 자식 클래스에서 재정의)으로 구현됩니다.
- 장점: 같은 메서드 이름으로 다양한 행동을 할 수 있어 코드의 유연성과 확장성을 제공합니다.
🔽 예시
class Bird:
def fly(self):
return "Bird is flying"
class Airplane:
def fly(self):
return "Airplane is flying"
def make_it_fly(flyable):
print(flyable.fly())
bird = Bird()
airplane = Airplane()
make_it_fly(bird) # Bird is flying
make_it_fly(airplane) # Airplane is flying4. 추상화 (Abstraction)
- 정의: 복잡한 시스템을 단순화하기 위해 중요한 특성만을 노출하고, 세부적인 구현 사항은 숨기는 것입니다. 추상화는 주로 추상 클래스와 인터페이스를 통해 구현됩니다.
- 장점: 시스템의 복잡성을 줄이고, 객체 간의 상호작용을 단순화하여 유지보수를 용이하게 합니다.
🔽 예시
from abc import ABC, abstractmethod
class Shape(ABC):
@abstractmethod
def area(self):
pass
class Circle(Shape):
def __init__(self, radius):
self.radius = radius
def area(self):
return 3.14 * self.radius * self.radius
class Rectangle(Shape):
def __init__(self, width, height):
self.width = width
self.height = height
def area(self):
return self.width * self.height
circle = Circle(5)
rectangle = Rectangle(4, 6)
print(circle.area()) # 78.5
print(rectangle.area()) # 24요약
- 캡슐화: 데이터와 메서드를 객체로 묶어 숨김과 보호를 제공.
- 상속: 기존 클래스의 속성과 메서드를 재사용하여 새로운 클래스를 정의.
- 다형성: 동일한 메서드 호출이 다양한 객체에서 다르게 동작.
- 추상화: 복잡한 시스템을 단순화하여 중요한 부분만 노출.
📌 상속과 다형성(Polymorphism)의 차이점은?
상속
기존 클래스의 속성과 메서드를 재사용하여 새로운 클래스를 정의하는 방식
class Animal:
def speak(self):
return "Animal sound"
class Dog(Animal):
def speak(self):
return "Bark"
class Cat(Animal):
def speak(self):
return "Meow"
dog = Dog()
cat = Cat()
print(dog.speak()) # Bark
print(cat.speak()) # Meow
다형성
동일한 메서드 이름이 다양한 객체에서 다르게 동작하도록 하는 기능.
class Bird:
def fly(self):
return "Bird is flying"
class Airplane:
def fly(self):
return "Airplane is flying"
def make_it_fly(flyable):
print(flyable.fly())
bird = Bird()
airplane = Airplane()
make_it_fly(bird) # Bird is flying
make_it_fly(airplane) # Airplane is flying
📌 SQL과 NoSQL의 차이는 무엇인가요?
SQL 데이터베이스
- 정의: SQL(Structured Query Language) 데이터베이스는 관계형 데이터베이스(RDBMS)로, 데이터가 테이블 형태로 구조화되어 저장됩니다. 데이터는 행과 열로 구성된 표(테이블)에 저장되며, SQL을 사용하여 데이터베이스를 쿼리하고 조작합니다.
스키마가 고정되어 있어 나중에 스키마 변경이 수정이 쉽지 않을 수 있습니다. - 예시: MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server
- 사용 사례: 금융 거래, ERP 시스템, 전통적인 비즈니스 애플리케이션 등 높은 데이터 무결성과 복잡한 쿼리가 필요한 경우.
NoSQL 데이터베이스
- 정의: NoSQL(Not Only SQL) 데이터베이스는 관계형 모델을 따르지 않으며, 다양한 데이터 모델(문서, 그래프, 키-값, 열 기반 등)을 지원합니다. 데이터는 테이블이 아니라 다양한 형식으로 저장될 수 있습니다.
데이터 모델이 유연하며, 데이터 삽입 전에 스키마를 정의할 필요가 없습니다. 각 데이터 항목이 서로 다른 구조를 가질 수 있습니다. - 다양한 쿼리 방법: SQL과 같은 표준화된 쿼리 언어가 없으며, 각 NoSQL 데이터베이스는 자체 쿼리 방식이나 API를 제공합니다.
- 예시
- 문서 기반: MongoDB, CouchDB
- 키-값 저장소: Redis, DynamoDB
- 열 기반: Cassandra, HBase
- 그래프 데이터베이스: Neo4j, Amazon Neptune
- 대규모 데이터, 비정형 데이터, 빠른 읽기/쓰기 성능이 필요한 경우, 소셜 네트워크, 실시간 분석, IoT 데이터,
스키마 변경을 많이 해야하는 경우 등, 스타트업에서 많이 사용함.
요약
- SQL 데이터베이스: 구조화된 데이터를 표 형태로 저장하며, 강력한 데이터 무결성과 일관성을 제공하는 반면, 수직 확장에 제한이 있습니다.
- NoSQL 데이터베이스: 다양한 데이터 모델을 지원하며, 유연한 스키마와 수평 확장을 통해 대규모 데이터와 높은 성능을 제공합니다.

📌 SQL에서 JOIN의 종류와 각각의 차이점은?
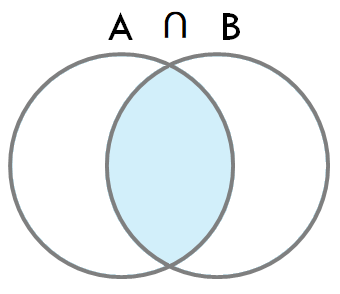
1. INNER JOIN
- 정의: 두 테이블 간의 일치하는 레코드만을 반환합니다. 즉, 두 테이블의 공통된 열 값이 일치하는 행만 포함됩니다.
(가장 일반적인 Join 타입)
SELECT employees.name, departments.dept_name
FROM employees
INNER JOIN departments ON employees.dept_id = departments.dept_id;
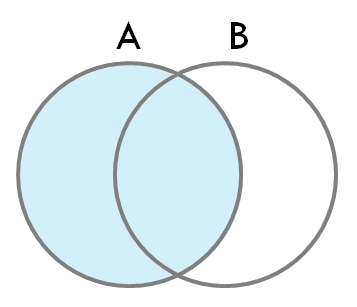
2. LEFT JOIN (또는 LEFT OUTER JOIN)
- 정의: 왼쪽 테이블의 모든 레코드를 반환하고, 오른쪽 테이블에서 일치하는 레코드가 있으면 포함합니다. 오른쪽 테이블에 일치하는 레코드가 없으면 NULL 값이 반환됩니다.
- 특징: 왼쪽 테이블의 모든 행이 결과에 포함됩니다.
SELECT employees.name, departments.dept_name
FROM employees
LEFT JOIN departments ON employees.dept_id = departments.dept_id;
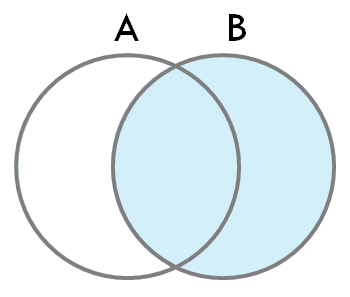
3. RIGHT JOIN (또는 RIGHT OUTER JOIN)
- 정의: 오른쪽 테이블의 모든 레코드를 반환하고, 왼쪽 테이블에서 일치하는 레코드가 있으면 포함합니다. 왼쪽 테이블에 일치하는 레코드가 없으면 NULL 값이 반환됩니다.
- 특징: 오른쪽 테이블의 모든 행이 결과에 포함됩니다.
SELECT employees.name, departments.dept_name
FROM employees
RIGHT JOIN departments ON employees.dept_id = departments.dept_id;
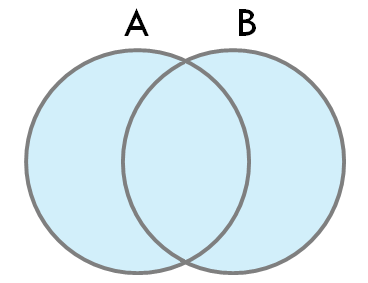
4. FULL JOIN (또는 FULL OUTER JOIN)
- 정의: 왼쪽 테이블과 오른쪽 테이블의 모든 레코드를 반환합니다. 두 테이블 간의 일치 여부에 상관없이 데이터를 포함하며, 일치하지 않는 경우 NULL 값이 반환됩니다.
- 특징:
- 두 테이블의 모든 행이 결과에 포함됩니다.
- 두 테이블 간의 데이터가 일치하지 않는 경우 NULL로 채워집니다.
SELECT employees.name, departments.dept_name
FROM employees
FULL JOIN departments ON employees.dept_id = departments.dept_id;
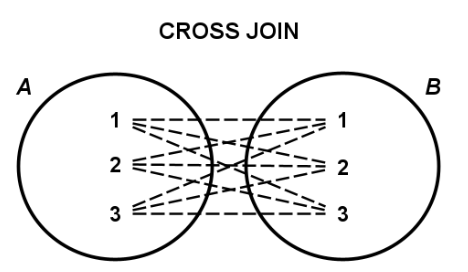
5. CROSS JOIN
정의: 두 테이블 간의 모든 가능한 조합(데카르트 곱)을 반환합니다. 즉, 첫 번째 테이블의 각 행이 두 번째 테이블의 모든 행과 결합됩니다.
특징:
- 두 테이블의 모든 조합을 포함하므로 결과 집합이 매우 클 수 있습니다.
- 일반적으로 조인 조건이 없는 경우 사용되며, 조인 조건을 제공하지 않습니다.
SELECT employees.name, departments.dept_name
FROM employees
CROSS JOIN departments;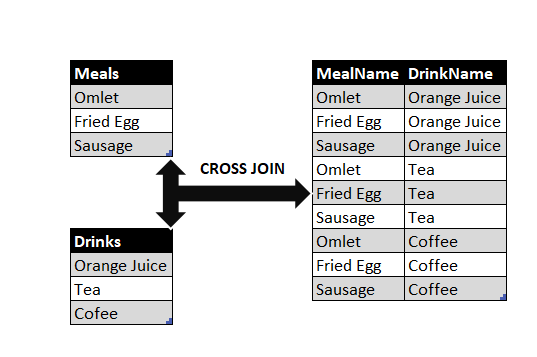
6. SELF JOIN
정의: 동일한 테이블을 두 번 조인하는 것입니다. 이는 테이블 내의 관계를 정의하거나 자기 참조적 데이터를 처리할 때 사용됩니다.
특징:
- 테이블이 자기 자신과 조인됩니다.
- 테이블의 데이터를 다른 행과 비교하거나 결합할 때 유용합니다.
SELECT e1.name AS EmployeeName, e2.name AS ManagerName
FROM employees e1
INNER JOIN employees e2 ON e1.manager_id = e2.employee_id;
요약
- INNER JOIN: 일치하는 행만 반환.
- LEFT JOIN: 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행 반환.
- RIGHT JOIN: 오른쪽 테이블의 모든 행과 왼쪽 테이블의 일치하는 행 반환.
- FULL JOIN: 양쪽 테이블의 모든 행을 반환, 일치하지 않는 경우 NULL.
- CROSS JOIN: 모든 가능한 행 조합을 반환.
- SELF JOIN: 동일한 테이블을 자기 자신과 조인하여 자기 참조적 데이터를 처리.
📌 서브쿼리와 조인의 차이점은?
- 사용 목적:
- 서브쿼리는 복잡한 SQL 쿼리문에 많이 사용된다. 보통은 메인 쿼리라고 부르는 외부 쿼리가 있고, 외부 쿼리 내에 다른 쿼리문, 즉 내부 쿼리가 있는 구조다.
- 조인은 여러 개의 쿼리를 필요로 하지 않는다. 조인의 역할은 2개 혹은 그 이상의 테이블을 연결하고, 데이터를 결합하여 관계를 기반으로 정보를 통합할 때 사용한다.
- 구문 위치:
- 서브쿼리는 SELECT, WHERE, HAVING, FROM 등의 절에 포함될 수 있습니다.
- 조인은 주로 FROM 절에서 테이블을 결합할 때 사용합니다.
- 성능:
- 서브쿼리는 복잡한 쿼리에서 성능 문제가 발생할 수 있습니다. 특히 서브쿼리가 많은 경우 성능 저하를 유발할 수 있습니다.
- 조인은 성능이 더 나을 수 있으며, 데이터베이스 엔진은 조인을 최적화하는 데 많은 노력을 기울입니다.
조인과 서브쿼리는 때로 동일한 결과를 얻어 어느 것을 사용해도 상관이 없을 때가 있다.
하지만, 상황에 따라 조인을 사용하는 것이 훨씬 좋을 때도 있고, 반면에 서브 쿼리를 사용하는 것이 좋을 때도 있다.
📌 캡슐화와 은닉화의 차이점은?
🔽 캡슐화와 은닉화 설명
캡슐화 (Encapsulation)
- 정의: 캡슐화는 객체의 데이터(속성)와 이 데이터를 조작하는 방법(메서드)을 하나의 단위로 묶는 것을 말합니다. 이는 객체가 자신을 관리하는 방식으로, 객체 내부의 상태와 동작을 함께 캡슐화하여 하나의 단위로 제공합니다.
- 목표: 객체가 데이터를 관리하고 조작할 수 있는 인터페이스를 제공하여 외부 코드가 객체의 내부 상태를 직접 수정하지 못하도록 합니다. 이렇게 함으로써 객체의 무결성을 유지하고 코드의 재사용성과 유지보수성을 높입니다.
- 파이썬 예시:
class BankAccount:
def __init__(self, balance):
self.__balance = balance # private 속성
def deposit(self, amount):
if amount > 0:
self.__balance += amount
def withdraw(self, amount):
if 0 < amount <= self.__balance:
self.__balance -= amount
def get_balance(self):
return self.__balance
은닉화 (Information Hiding)
- 정의: 은닉화는 객체의 내부 구현 세부사항을 숨기고, 객체의 사용자가 내부 구조에 의존하지 않도록 하는 것입니다. 이는 객체의 내부 상태를 외부에서 직접 접근할 수 없게 하고, 객체가 제공하는 공용 인터페이스를 통해서만 상호작용할 수 있도록 합니다.
- 목표: 객체의 내부 구현을 변경하더라도 외부 코드에는 영향을 주지 않도록 하여 코드의 안정성과 유지보수성을 향상시킵니다. 이는 객체의 내부 로직이 외부와의 약속에 맞게 설계되도록 합니다.
- 파이썬 예시:
class Car:
def __init__(self):
self._engine_status = 'off' # protected 속성
def start_engine(self):
self._engine_status = 'on'
def stop_engine(self):
self._engine_status = 'off'
def __check_engine_status(self): # private 메서드
return self._engine_status- 캡슐화는 객체의 상태와 동작을 묶는 방법입니다. 즉, 객체가 제공하는 메서드를 통해서만 내부 상태를 수정하거나 조회할 수 있도록 합니다.
- 은닉화는 내부 구현 세부사항을 숨기는 방법입니다. 객체의 내부 구현(상태나 메서드)을 외부에서 접근할 수 없도록 하고, 객체가 제공하는 공개된 인터페이스를 통해서만 상호작용할 수 있도록 합니다.
💡 면접 Tip
객체지향에 관한 설명 중, 내가 절차지향과 비교하여 설명했는데 그 부분을 튜터님이 칭찬해주셨다.
✔가능하다면 대응되는 개념과 비교하여 설명하기!
그리고 단순히 질문에 대한 기술적인 답변 뿐이 아니라, 나의 경험을 녹아내서 답변하면
면접관의 흥미도 끌어낼 수 있고, 다음 질문들도 나의 경험과 관련된 질문을 받을 수 있기 때문에 답변하기에도 좋을 거라는 조언을 받았다.
✔ 답변할 때 나의 경험과 연관지어 설명하고, 내가 했던 경험을 어필하여 관련 질문을 유도하자!
'스파르타 내일 배움 캠프 AI 웹개발 과정 > 면접준비' 카테고리의 다른 글
| 개발자 기술면접 대비 질문/답변 리스트 (초급) (0) | 2024.08.06 |
|---|
